- Zero Trust
- AI Security
- Security Architecture
- ·
-
Jan 17, 2026
The Great Decoupling Part II: From Designing the Loop to Running It
I put a small AI model in charge of my firewall. Then I hired a larger model to watch it. Not just to save time - but because humans are no longer fast enough to stop machine-led attacks.

Nikola Novoselec
Founder & Zero Trust Architect
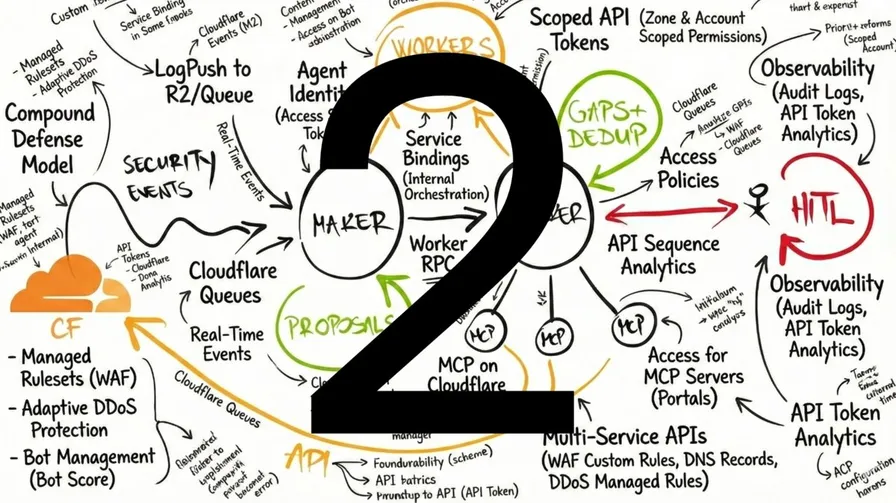
In Part I of “The Great Decoupling,” I described the theory - Context Management as the new Memory Management, the Maker-Checker pattern borrowed from banking, and why Zero Trust becomes the great equalizer for AI governance.
This is what happened when I actually built it.
The broader context: AITL is part of a Zero Trust strategy. The industry has spent years talking about Zero Trust for humans - verify identity, enforce least privilege, never trust by default. As organizations roll out Zero Trust Edge capabilities on platforms like Cloudflare, the question becomes: if we don’t trust humans by default, why would we trust autonomous AI systems? The same principles apply: every agent needs explicit identity, scoped permissions, and full attribution. Every action needs verification before execution. Trust is earned through governance, not assumed through deployment.
I put a small AI model in charge of my firewall. Then I hired a larger model to watch it. Not just to save time - but because humans are no longer fast enough to stop machine-led attacks.
1. Why Traditional Security Operations Fail
Let me start with the problem I was trying to solve. Alert fatigue is a hidden balance sheet liability. Security analysts receive thousands of events daily. They become numb. Critical signals get buried in noise. You’re burning budget on noise instead of signals.
Response latency creates windows of opportunity. AI-powered attackers move in seconds - probing, adapting, exploiting. Humans context-switch, attend meetings, sleep. The gap between detection and response is where breaches happen.
Manual processes don’t scale economically. More alerts require more analysts, creating coordination overhead. Organizations face a choice between accepting risk or unsustainable headcount growth.
Full automation creates liability. Fire-and-forget playbooks work until one bad change blocks legitimate traffic. For a critical infrastructure provider, an automated system that blocks legitimate services isn’t a technical error - it’s mission-critical failure.
Agent-in-the-Loop addresses all four problems simultaneously.
2. Split Duties for Trust
Here’s where the theory meets implementation. A single AI doing everything is tempting but wrong. The same model that proposes an action shouldn’t validate it. That’s like having the same person write and approve their own expense reports.
The Maker acts as the Hunter - aggressively flagging every potential threat. It scans security events, identifies patterns, and generates action proposals. Fast, responsive, comprehensive.
The Checker acts as the controller - ensuring the organization doesn’t block legitimate traffic. It receives proposals and evaluates them against policy. It kills the noise, ensuring only well-reasoned actions proceed.
Neither can act alone. Both must agree for autonomous execution.
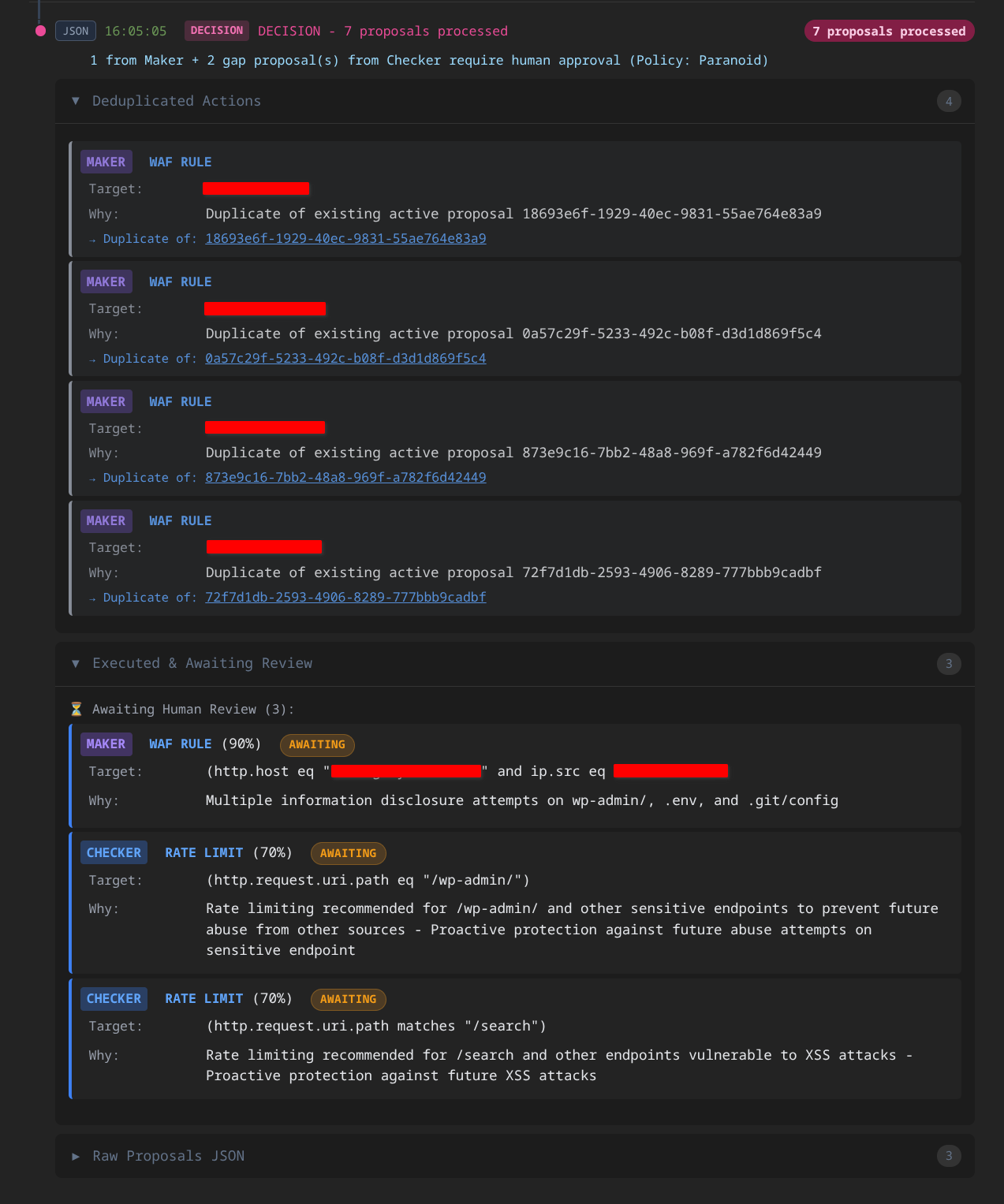
What makes this powerful: AITL analyzes the gaps - both what slipped through AND what got blocked.
Hunting missed threats: When 12 sources from different networks probe the same endpoints - threat scores elevated but under blocking threshold, no rule matches, rates under limit - each request looks benign in isolation. Correlated? Coordinated reconnaissance that no single detector caught.
Eliminating false positives: When legitimate traffic gets blocked repeatedly, the Checker identifies the pattern and proposes policy adjustments. Defense that blocks real users is broken defense.
The Checker isn’t just a filter - it’s a strategist. It can augment the Maker’s proposals - adding a rate limit where the Maker only recommended IP blocks, or adjusting scope where the original proposal was too broad. These augmentations carry lower confidence scores by design, which means they escalate to human review in all but the most aggressive policy levels.
Neither agent sees the full picture alone. Together, they optimize the entire security posture - and escalate to humans when confidence is low or policy demands it.
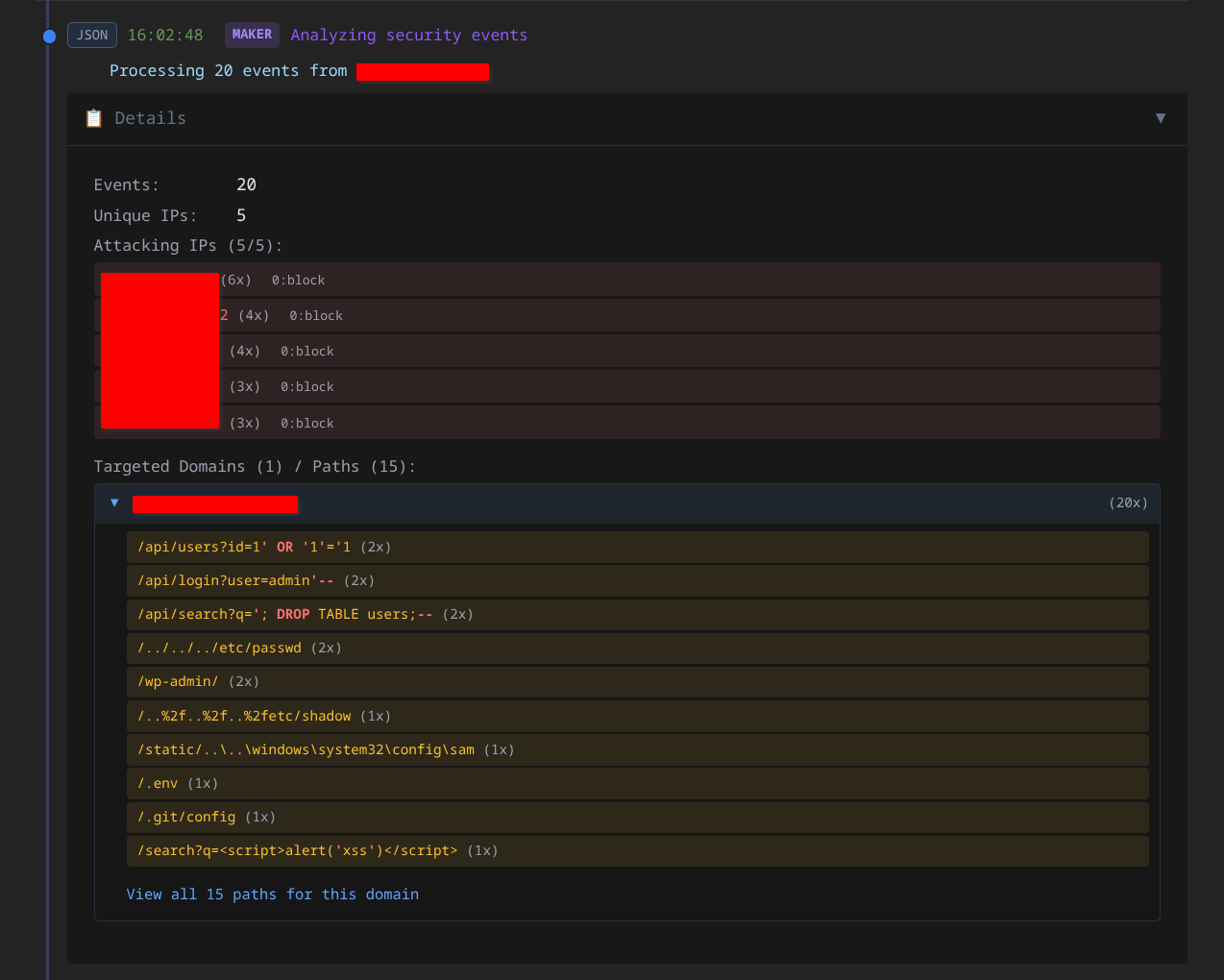
3. Graduated Autonomy: The Production Reality
This is where clean diagrams didn’t survive contact with live internet traffic. When does the system auto-execute versus escalate to humans? This governance question determines success or failure.
The architecture supports four trust levels - not just settings, but stages in a managed transition:
Stage 1 - Paranoid: Never auto-approve. Every action escalates. The system recommends; humans decide. Learning mode.
Stage 2 - Conservative: Auto-approve only low-risk, narrow-scope actions. Single IP blocks with clear evidence. Everything else escalates.
Stage 3 - Moderate: Broader automation with moderate scope. IP range blocks and targeted rate limits with medium confidence. Augmented proposals (that add nuance vs pure blocks) escalate for review.
Stage 4 - Aggressive: Most actions proceed with minimal escalation. Network-level blocks and broad rate limits with lower confidence thresholds. Reserved for high-trust environments with mature governance.
The critical insight: Start paranoid. Watch the system recommend while approving everything manually. Build confidence before expanding autonomy.
I projected a transition to Conservative within hours. In reality, the system remained in Paranoid for two days - not because the AI was wrong, but because calibrating what confidence thresholds meant in practice took longer than expected. Rushing this calibration creates the exact risks the architecture is designed to avoid.
Current state: Conservative mode with approximately 15-20% auto-approval. I’m the sole operator reviewing proposals on infrastructure that mirrors enterprise production - real services behind Cloudflare, exposed to real threats - testing the governance model before scale. In an enterprise deployment, this becomes Infrastructure as Code with PR-based approvals to prevent configuration drift.
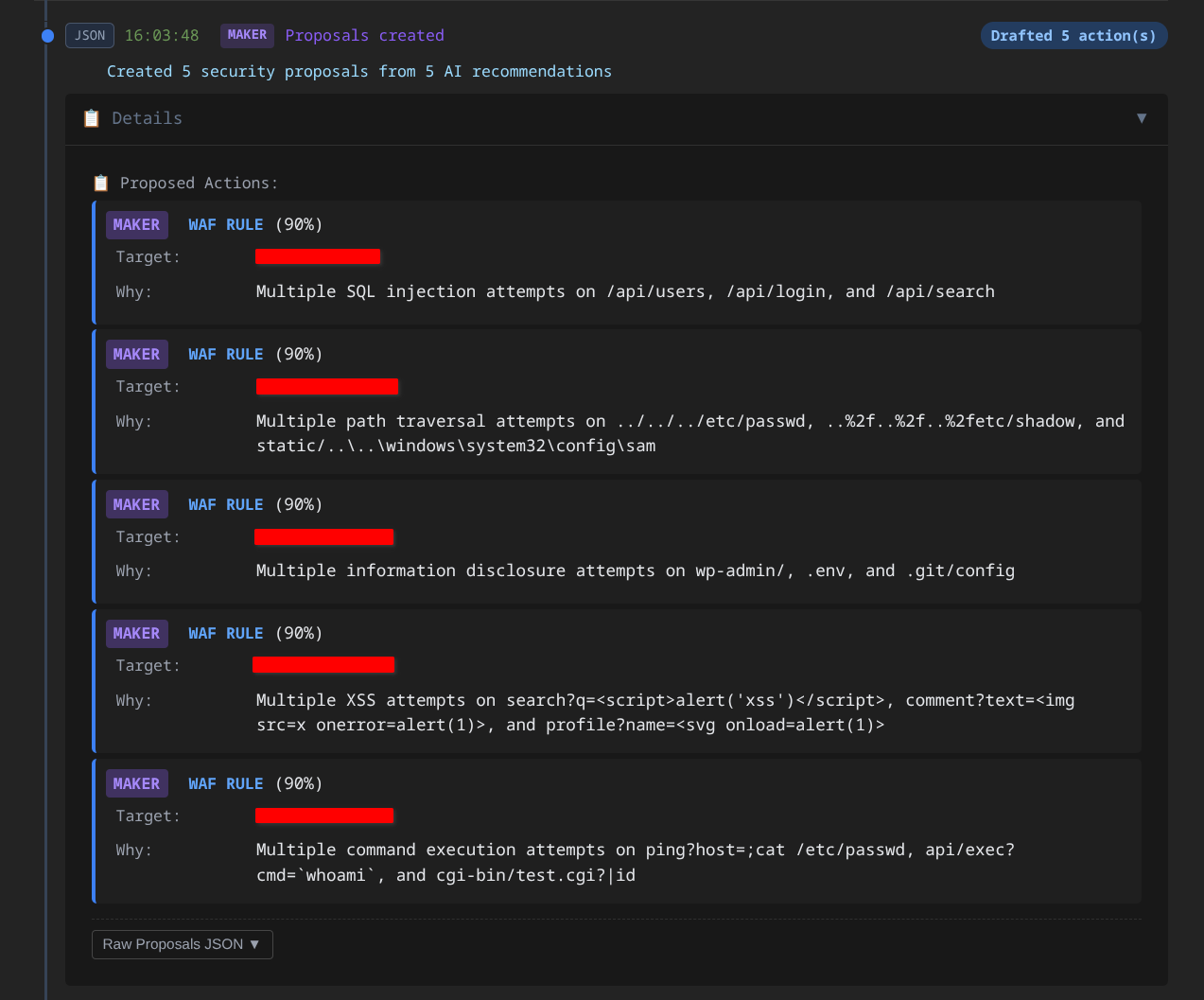
4. What Goes Wrong
Here’s what broke - and how I fixed it.
AI hallucinations - confidently wrong outputs - become operational outages. In early testing, the AI generated a security policy that looked perfect but would have crashed the network. The fix: multi-layer validation with hard-coded safety gates at every step. If any layer fails validation, the system escalates to humans. These safety gates are the ultimate authority - no matter how clever the AI becomes. This is why the Checker exists: to protect operational continuity.
Individual evaluation misses coordinated attacks. The first design evaluated proposals one at a time. Each detector - WAF at the edge, Access for identity - is sophisticated on its own, but operates in its own domain. AITL adds a correlation layer: when multiple authenticated users from unusual locations hit the same endpoints with slightly elevated threat scores but no WAF blocks, that’s a coordinated campaign neither system flagged alone. The fix: batch evaluation that correlates across security domains.
Rollback isn’t optional - it’s a business requirement. Every executed action must store what’s needed to reverse it. One-click rollback in the admin interface. A manual override kill switch that disables all auto-execution if something goes wrong. This isn’t a feature - it’s a governance mandate.
False positives are learning opportunities. For the first two days, the system ran in shadow mode - evaluating everything, blocking nothing. An “Ignore” option teaches the system what to suppress. The system learns without retraining the AI.
Telemetry is untrusted input. Attackers control User-Agent strings, paths, query parameters - all of which flow into event logs. The fix: strict input schemas, no free-text interpolation into prompts, and allowlisted actions only. The AI sees structured data, not raw attacker-controlled strings.
Observability is non-negotiable. When something goes wrong - and something always goes wrong - the organization needs the complete story. Which agent made the decision? What evidence supported it? Full audit trails transform debugging from guesswork to forensics.
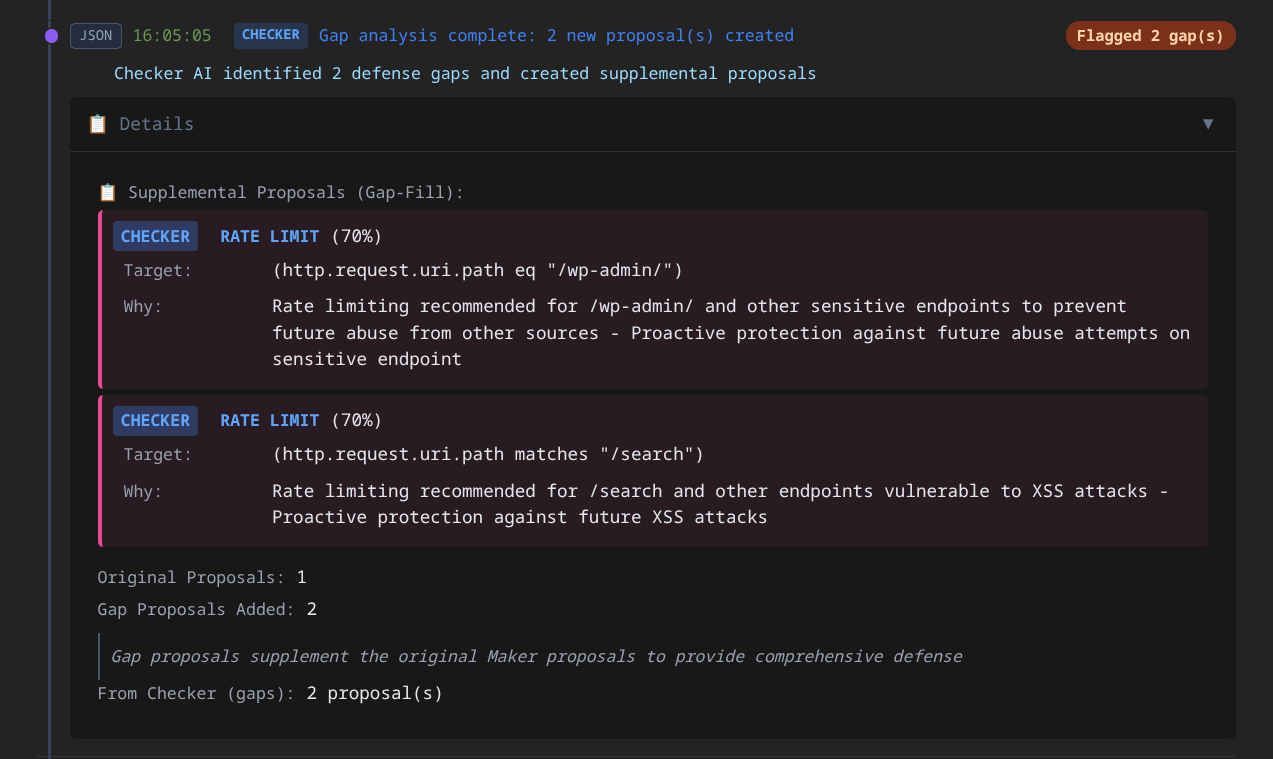
5. The Governance Framework
Hardening a prototype isn’t just about making it work - it’s about making autonomous systems auditable before they go to production. This matters for compliance. Forensic audit trails aren’t optional.
Distinct identity per agent. Shared credentials are a security anti-pattern. Each agent gets its own identity. When something goes wrong, the forensic question has an answer: which agent did this?
Scoped permissions per capability. Each function gets exactly the permissions it needs. The component that reads events cannot modify rules. The component that creates rules cannot delete critical records. If any credential is compromised, the blast radius is contained.
Policy-governed tool access. The same governance framework that controls human access controls agent access. These questions have explicit answers in policy, not implicit assumptions in code.
Complete attribution for every action. Not “the system blocked this” but “agent-checker approved proposal #1847 at timestamp, based on 47 security events, with 94% confidence.” Auditors can trace any change back to specific evidence and reasoning.
The Bottom Line
Here’s what it comes down to. In Part I, I said the future of engineering isn’t about being in the loop - it’s about designing it. Part II is about what happens when you actually run it.
The industry has to move from a world where humans write rules to catch attackers, to a world where humans write policies to guide agents. This isn’t the end of human judgment. It’s the beginning of scalable human judgment - where human wisdom is encoded in governance frameworks that AI executes consistently, tirelessly, and auditably.
The organizations that figure this out first will have meaningful advantages. The organizations that don’t will be stuck choosing between unsustainable manual processes and ungovernable automation.
Agent-in-the-Loop is how you actually build it - the architecture that encodes human wisdom into governance frameworks that execute consistently, tirelessly, and auditably. And it’s live - real agents making real security decisions with real governance, proving the model before scale.
Prêt à transformer votre posture de sécurité ?
Que vous ayez besoin d'un Zero Trust Maturity Assessment, d'une revue d'architecture de sécurité ou de conseils sur l'intégration de l'IA dans vos opérations - discutons de votre situation spécifique. Pas de processus de vente. Pas d'entretiens préliminaires avec des juniors. Une conversation directe sur vos défis.
Ans
De l'évaluation à l'architecture jusqu'à l'implémentation
Secteurs
Logistique, transports, finance, secteur public
Indépendant
Aucun partenariat. Aucune commission. Vos intérêts uniquement.